Creating guardrails
Guardrails are configurable safety controls that limit what an AI agent can say or do. They protect users and businesses by preventing inappropriate, unsafe, or non-compliant responses. It ensures the agent communicates responsibly, securely, and consistently. Guardrails affect agent responses and user inputs the agent processes. Refer to Building and agent to learn more.
Blocked message
When guardrails are triggered, the agent responds with the Blocked Message listed in the agent’s Guardrails screen. For example, a blocked message could be "I'm sorry, but I can only provide the status of an order and support contact information." The agent responds with a blocked message for any triggered guardrails to avoid indicating which specific word or phrase caused the response.
Default guardrails
By default, all agents created in the Agent Designer have the following guardrails applied in the backend:
- Profanity detection - prevents vulgar or offensive responses
- Prompt attack prevention - Detects and blocks attempts to manipulate agent behavior and its guardrails through adversarial prompts.
- General harmful content categories - blocks categories such as hate speech, violence, self harm, and sexual content
Guardrail settings
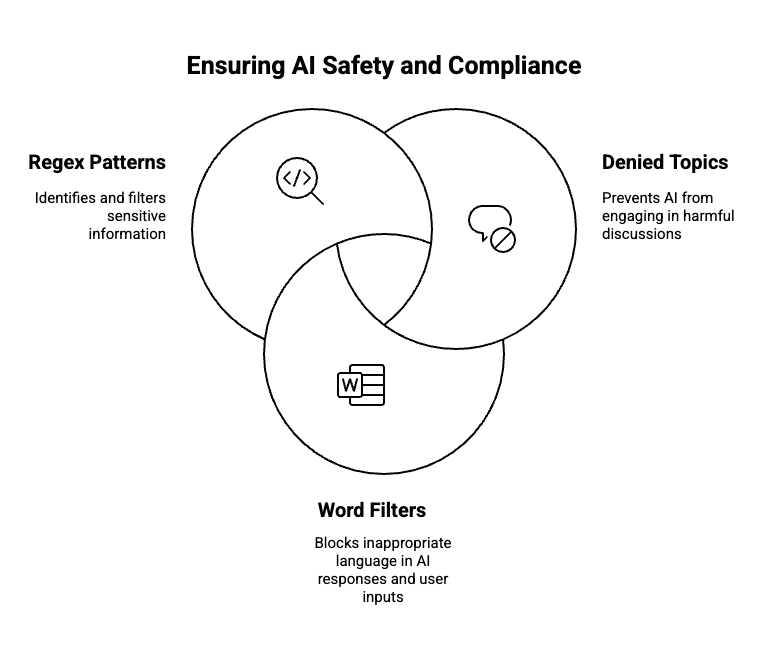
In addition to default guardrails, you can set the following safety mechanisms:
Denied topics
Themes or subjects that you clearly define as off-limits for the AI agent. When a user input or model response matches a denied topic, the system intervenes to block the content and returns a pre-defined message instead.
Each denied topic includes a label for the topic, a definition, and sample phrases. For example:
- Name: “Investment Advice”.
- Definition: Inquiries, guidance, or recommendations about the management or allocation of funds or assets with the goal of generating return or achieving specific financial objectives.
- Sample phrases: Should I invest in gold? Is investing in stocks better than bonds?”
You can define up to 30 denied topics per guardrail. Each denied topic can have up to five sample phrases.
Word filters
Word filters are lists of words or phrases that should not appear in agent responses or user messages. When a filtered word is detected, the agent blocks the response or input containing that word. It then returns a pre-defined blocked message. For example, you can add words like competitor names to block discussions about competitor's offerings or add phrases like "guarantee" to prevent the agent from using this word when mentioning pricing or sales.
Regex pattern
A regex expression or pattern is a string of characters that define a rule for matching text. Agents can identify credit card numbers based on a regex pattern and block the user input or agent response. Regex patterns help to block sensitive data such as social security numbers and credit card numbers. For example, ^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$ for email addresses and ^\d{3}-\d{2}-\d{4}$ for social security numbers.
How are guardrails implemented?
Guardrails are processed in parallel to minimize latency. All guardrail policies are applied to both the user’s input text and the agent’s generated responses.
For Denied topics, the Large Language Model (LLM) analyzes the user’s input to check for prohibited subjects. It generates a confidence score based on this analysis. If the confidence score is above 80%, the system replies with a Blocked Message.
Guardrail best practices
Avoid false positives
A false positive occurs when a valid user prompt or agent response is blocked because a guardrail rule is too broad. If users are hitting blocked messages for legitimate requests, review the relevant denied topic definition, word filter, or regex pattern and narrow its scope so it only catches what you intend.
Check both input and output
Guardrails apply to both the user’s input prompt and the agent’s generated response. A common oversight is configuring guardrails only with user-facing scenarios in mind. If your agent retrieves data that could contain sensitive fields, make sure your guardrail policies are tested against agent output as well as user input.
Narrow your regex and keyword patterns
Wide patterns can trigger unintended partial matches. For example, a keyword filter for "shot" intended to block violent content will also match "troubleshoot" and "snapshot." Test your patterns against real examples before deploying and refine them to be as specific as possible.
For help diagnosing guardrail issues using the agent trace, refer to Testing and troubleshooting an agent.
