OP Database with RAG - Partner operation
The OP Database with RAG — Partner operations define how to interact with your database and represent a specific action (INSERT, GET, UPDATE, UPSERT, DELETE, and STORED PROCEDURE) to be performed against one/many database objects. Additionally, there is a VERSION operation to see which build you are using. Apart from the UPSERT and STORED PROCEDURE operations, all the other operations can be classified as:
-
Standard Operation: Uses prepared SQL statements entered by the user.
-
Dynamic Operation: Uses the statement class to build dynamic SQL queries during the runtime based on the user’s input.
-
Entity Operation: Uses the statement class to build a dynamic SQL query during the runtime based on the primary keys. This operation is performed on a single entity.
Browse
The Browse feature connects to a target database, collects service metadata, and leverages this information to generate various fields. These include but are not limited to, the request and response profiles, primary keys, metadataContainer (containing table metadata), and the SQL query (applicable for standard operations only).
Error codes
The error codes below help identify and troubleshoot various issues that may arise during the operation of the database connector. Each code is grouped by category, making it easier to understand the type of issue and take appropriate action.
- Configuration Errors (E1##): These codes indicate setup issues, such as connection parameters or driver-related problems.
- Payload Errors (E2##): These codes capture errors related to invalid input data, covering both syntax and content validation.
- Connection Errors (E3##): Codes in this category represent issues with network communication or data transmission, including timeouts and interruptions.
- SQL Errors (E4##): These codes are triggered by SQL operation failures, including general execution and batch processing errors.
- Business Validation Errors (E5##): These codes signal validation failures in the business logic, such as discrepancies in affected row counts.
- Unknown Errors (E9##): This general category covers unhandled or unexpected issues that don’t fall into other categories.
| Error Code | Name | Description | Investigation & Mitigation |
|---|---|---|---|
| E1## Configuration Errors | |||
| E101 | CONNECTION CONFIGURATION ERROR | An error in the configuration for establishing a connection. | Verify all connection parameters (host, port, credentials, and so on). Check for typos and ensure the database is reachable. Test connectivity using a tool (for example, telnet, ping). NOTE: If using PostgreSQL in runtime cloud and encountering file permission issues, add this connection property: Key: sslfactoryValue: org.postgresql.ssl.NonValidatingFactory |
| E102 | OPERATION CONFIGURATION ERROR | An issue with configuring the connector's operation parameters. | Review connector-specific settings (for example, operation type, payload mappings). Refer to the documentation to ensure the parameters are valid. |
| E103 | JDBC DRIVER ERROR | A failure related to loading or interacting with the JDBC driver. | Check if the JDBC driver is correctly installed and compatible with your connector. Update the driver to the latest version, and ensure it is included in the classpath. |
| E104 | BROWSER ERROR | An issue with accessing the browser for connector configuration or execution. | Ensure the connection is valid as well as any browser configuration options. |
| E105 | METADATA CONTAINER ERROR | An error occurs when accessing or reading metadata containers. | Ensure the metadata exists and is valid. If overridden, confirm that the metadata JSON contains the correct data types. If the database schema changes, re-run the browser to refresh the metadata. |
| E2## Payload Errors | |||
| E201 | INPUT DOCUMENT FORMAT | A syntax error in the input request document. | Validate the input against the required format. (Request Profile) |
| E202 | VALIDATION ERROR | A semantic error in the input request, such as invalid data types or required fields missing. | Ensure all fields exactly match the database schema, including names and data types. |
| E3## General Connection Errors | |||
| E301 | CONNECTION TIMEOUT | The connection attempt timed out, potentially due to network issues or an unresponsive server. | Check the network connectivity and database server status. Increase the timeout setting if necessary. |
| E302 | IOEXCEPTION | An IOException was thrown, indicating an issue with data transmission or I/O operations. | Inspect network logs for dropped packets. Check if intermediate firewalls or proxies are blocking the communication. |
| E303 | INTERRUPTED | The connection or operation was interrupted, potentially due to a thread interruption. | Verify thread stability and ensure no unexpected cancellations in the process logic. Review logs for details of the interruption cause. |
| E4## SQL Errors | |||
| E401 | SQL EXCEPTION | A general SQL exception occurred, often related to query execution errors. | Review query syntax using a database client (for example, DBeaver, pgAdmin). Validate columns, tables, constraints, and data types. Note that some data types (for example, binary) require specific formatting options. |
| E402 | SQL BATCH EXCEPTION | An error occurred while executing a batch SQL operation, typically a BatchUpdateException. | Check batch statements for errors (for example, invalid updates). Review database logs for context. Verify columns, tables, and data types, ensuring proper configuration for data types like binary. |
| E5## Business Validation Errors | |||
| E501 | INVALID AFFECTED COUNT | The affected row count after executing a query did not match the expected validation criteria. | Check the query logic for correctness. Confirm that input data aligns with the validation rules (for example, expected row counts). |
| E9## Unknown Errors | |||
| E999 | UNKNOWN | An unhandled or unknown error occurred, serving as a general fallback for uncategorised exceptions. | Review error logs for details. |
If your process experiences issues such as timeouts, unresponsiveness, or hanging operations, there may be a database lock caused by long-running queries or processes.
- Use database management tools like
pg_stat_activity(PostgreSQL) orsys.dm_exec_requests(MSSQL) to identify and terminate these queries or processes.
Additionally, if the process hangs indefinitely, it could indicate a deadlock in the database due to unfinished transactions:
-
Investigate using tools such as
SHOW ENGINE INNODB STATUS(MySQL) orsp_who2(MSSQL) to identify deadlocks. -
Ensure your process follows proper transaction handling and uses consistent isolation levels to prevent future occurrences.
Metadata Container
The metadata is a JSON string containing all information about a table's fields, which is automatically generated by the browse but can also be provided manually.
This information is needed throughout the execution of the operation, such as helping with conversions between JDBC and JSON. Boomi makes a call to the database to get this information each time it is needed. However, by generating the metadata during the browse step, no additional calls are necessary during the operation's execution, as all necessary information is stored as a parameter.
Metadata Structure
The metadata structure consists of key attributes for each database column:
-
jdbcType: The JDBC type of the field.
-
jsonType: The corresponding JSON type of the field.
-
format: (Optional) Specifies the format of the field, such as for dates or timestamps.
- Example:
"yyyy-MM-dd HH:mm:ss"for a timestamp field.
- Example:
-
length: The length or precision of the field.
-
jdbcTypeInfo: Specifies additional information, such as enums, JSON, binary input type, and array type.
-
uniqueKey: Indicates if the field is part of a unique key constraint.
-
primaryKey: Indicates if the field is a primary key.
-
autoKey: Indicates if the field is auto-incrementing.
-
nullable: Indicates if the field allows null values.
-
defaultField: Indicates if the field has a default value.
-
In: For stored procedures to specify whether the field is an input parameter.
-
Out: For stored procedures to specify whether the field is an output parameter.
Here is how the structure would look:
{
"column1": {
"jdbcType": "string",
"jsonType": "string",
"format": "string",
"length": "integer",
"jdbcTypeInfo": "string",
"uniqueKey": "boolean",
"primaryKey": "boolean",
"autoKey": "boolean",
"defaultField": "boolean",
"nullable": "boolean",
"in": "boolean",
"out": "boolean"
},
"column2": {
"jdbcType": "string",
"jsonType": "string",
"format": "string",
"length": "integer",
"jdbcTypeInfo": "string",
"uniqueKey": "boolean",
"primaryKey": "boolean",
"autoKey": "boolean",
"defaultField": "boolean",
"nullable": "boolean",
"in": "boolean",
"out": "boolean"
},
...
}
By configuring metadata manually, you optimize performance and reduce external dependencies during execution. This ensures that all necessary information for data operations is readily available, enhancing the efficiency and reliability of your integration processes.
Configuring Metadata
To configure metadata:
-
Identify each column in your database table.
-
Determine the appropriate JDBC type for each column.
-
Assign corresponding JSON types, formats (if applicable), lengths, and other attributes based on your table schema.
-
Ensure accuracy in specifying primary keys, auto-increment keys, and other constraints.
By configuring metadata manually, you optimize performance and reduce external dependencies during execution. This approach ensures that all necessary information for data operations is readily available, enhancing the efficiency and reliability of your integration processes.
The jdbcTypeInfo field provides additional information that complements specific JDBC types. It helps define how the data should be handled, particularly for more complex types like arrays, binary formats, or structured data. Below is a detailed breakdown of the jdbcTypeInfo for different JDBC types:
| JDBCType | JDBCTypeInfo | JSONType | Notes |
|---|---|---|---|
| ARRAY | 12 4 -6 6 8 | ARRAY | SQL code representing the array's data type. |
| BINARY | BASE64 HEXDEC BYTEARRAY | STRING STRING ARRAY | Binary format input type ("BYTEARRAY", "BASE64", "HEXDEC"). |
| VARBINARY | BASE64 HEXDEC BYTEARRAY | STRING STRING ARRAY | Binary format input type ("BYTEARRAY", "BASE64", "HEXDEC"). |
| LONGVARBINARY | BASE64 HEXDEC BYTEARRAY | STRING STRING ARRAY | Binary format input type ("BYTEARRAY", "BASE64", "HEXDEC"). |
| BLOB | BASE64 HEXDEC BYTEARRAY | STRING STRING ARRAY | Binary format input type ("BYTEARRAY", "BASE64", "HEXDEC"). |
| OTHER | JSON | Varies | Contains additional data type information (for example, "JSON" or "vector") to identify output. |
| STRUCT | "Konnekt"."complex" | String | Specifies the target struct type or table to cast the data to. |
| VARCHAR | enum | String | Specifies enum status. |
| VARCHAR | enum:"Konnekt"."primary_key_enum" | Specifies enum type to cast to, if applicable. |
Get Operation
| Video Type | Link |
|---|---|
| Setting up standard get operation | https://drive.google.com/file/d/1HZAlY1hCMHn3b8J2DD7OEj2IxXBJ1YyC/preview |
| Setting up dynamic get operation | https://drive.google.com/file/d/1dOyVFXaQjLECPpvzLu2awV8CjSQ01Pmc/preview |
| Setting up entity get operation | https://drive.google.com/file/d/12jwIo3CYrYnRUn-c1bhl7_jCuhrfJRBD/preview |
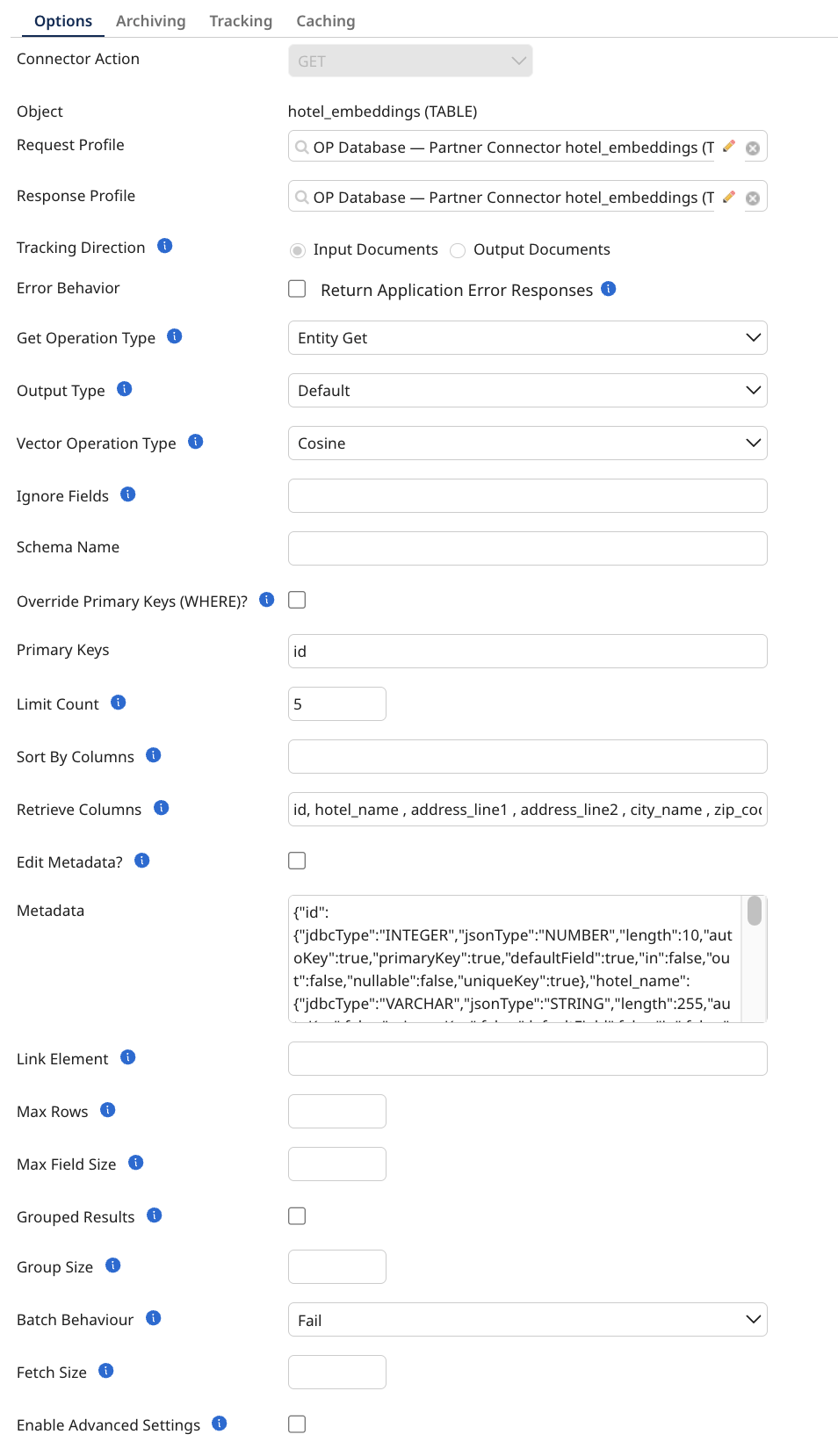
The Get operation is an inbound action used to retrieve records from the database based on parameters defined on the connector’s Parameters tab. It takes input parameters from the user and fetches the corresponding records. Additionally, the output can be batched using the Document Batching option provided in the Get-Import wizard. You can configure this operation using the following parameters:
-
Get Operation Type: A string specifying the type of get operation to use. The available options are:
-
Dynamic Get: The query is built dynamically at runtime, based on input parameters mapped to the WHERE clause of the SQL SELECT statement.
-
Standard Get: The user manually enters the SQL statements in the SQL Query field, and the parameters for the select query are taken from the input JSON.
-
Entity Get: Uses the statement class to build a dynamic SQL query during runtime based on primary keys. This operation retrieves a single entity.
-
-
Output Type: The response type for the connector. Options include the default output (records returned from the database) or the enrichment of the original user input data.
-
Vector Operation Type: Select the default type of operation to use when performing vector-based search calculations. This setting determines the mathematical method applied to evaluate vector similarity or distance. It supports the following:
- Postgres (with pgvector):
- Manhattan (Doesn’t support Binary Vectors)
- Euclidean (Doesn’t support Binary Vectors)
- Cosine (Doesn’t support Binary Vectors)
- Dot (Doesn’t support Binary Vectors)
- Jaccard (Binary Vectors Only)
- Hamming (Binary Vectors Only)
- **Oracle (tested using version 23.6):
- Manhattan
- Euclidean
- Cosine
- Dot
- Jaccard (Binary Vectors Only)
- Hamming
- MariaDB (from version 11.7):
- Euclidean
- Cosine
- MySQL (from version 9.0):
- Euclidean
- Cosine
- Dot
- MS SQL Server
- Euclidean
- Cosine
- Dot
- SAP Hana
- Euclidean
- Cosine
- Postgres (with pgvector):
-
Ignore Fields: A comma-separated list of fields to ignore to avoid exceptions caused by missing fields in the database metadata. (For Default output type only)
-
Schema Name: An optional string specifying the name of your schema. This overrides the value in the connection (MariaDB does not use schemas)
-
Discard Fields: A csv list of fields that should be discarded from the result set on GET operations.
-
SQL Query: A string that defines the SQL query to be used (Note: For more than one statement separated by a semicolon you need to append a connection property
allowMultiQueries=trueto the database URL.) (Only available in Standard Get) -
Override Primary Keys (WHERE)?: A boolean that when enabled allows manual modification of the primary keys (Only available in Entity Get)
-
Primary Keys (WHERE): A comma-separated list of all the primary keys that will be used to query the database. (WARNING: If left empty, it will affect all records!) (This will only be used if override primary keys is set to true) (Only available in Entity Get)
-
Limit Count: The maximum number of rows to be returned from the Database in a single request.
-
Sort By Columns: A comma-separated list of all the columns to sort by (This will only be used if override primary keys is set to true) (Only available in Entity Get)
-
Retrieve Columns: A comma-separated list of all the columns to return (This will only be used if override primary keys is set to true) (Only available in Entity Get)
-
Edit Metadata?: A boolean that when enabled allows manual modification of the metadata (When selected the browser will not update)
-
Metadata: A string value containing all information about a table's fields, which is automatically generated by the browse but can also be provided manually
-
Link Element: An optional string specifying the field, usually the primary key in the database, to split or group results into documents
-
Max Rows: An optional integer that specifies the maximum number of rows to be returned from the database in a single request.
-
Max Field Size: An optional integer specifies the limit for the maximum number of bytes that can be returned for character and binary column values in a ResultSetObject produced by this Statement object. If the limit is exceeded, the excess data is silently discarded. Applies only to
-
BINARY
-
VARBINARY
-
LONGVARBINARY
-
CHAR
-
VARCHAR
-
NCHAR
-
NVARCHAR
-
LONGNVARCHAR
-
LONGVARCHAR
-
-
Grouped Results: Group all results into one single document (json array).
-
Group Size: The number of records retrieved per output document for grouped results. (Only visible when Grouped Results is enabled.)
-
Batch Behavior: A string specifying the way batching should behave if some items within the batch do not match up. (Only visible when Grouped Results is enabled, ignored in Standard Get)
-
Fetch Size: An optional integer specifying the number of rows fetched when there is more than one row of results on select statements.
-
Advanced Settings: Enabling this parameter grants access to additional customization options for more specific configurations.
-
Sort Descending Prefix Delimiter: Defines the delimiter used to identify fields that should be sorted in descending order.
-
CSV Delimiter: Specifies the character used to separate fields within a CSV file.
-
Input Format
Dynamic Get
{
"WHERE": [
{
"column": "column name",
"operatior" "operator symbol (e.g. =)",
"value": "value"
}
]
}
Entity & Standard Get
{
"column name": "value"
}
Insert Operation
| Video Type | Link |
|---|---|
| Setting up standard insert operation | https://drive.google.com/file/d/1Bjy9EKqVd6Fh2lpBEHtA9sEzrvS-YBBN/preview |
| Setting up entity insert operation | https://drive.google.com/file/d/14cGjPH0mJx7fcQ0d5YvnrFhy6LQ2Vq3y/preview |
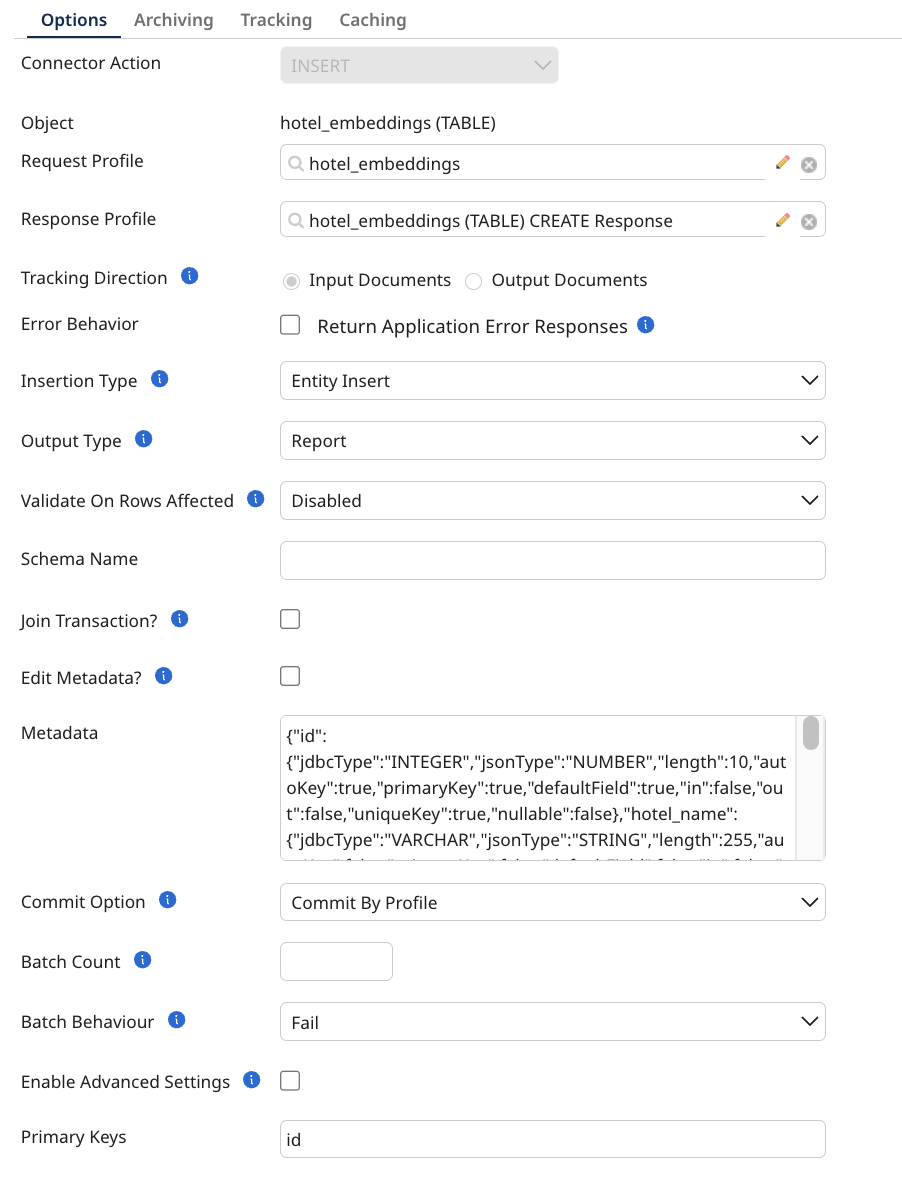
Insert is an outbound action used to insert new records into a database table. It supports JDBC statement batching, where the connector batches SQL statements based on input requests. Upon successful insertion, the IDs of the records are returned in the response. You can configure this operation using the following parameters:
-
Insert Type: A string specifying the type of insert operation to use. The available options are:
-
Standard Insert: The user provides the SQL statement and input parameters, and the connector executes the query based on the input.
-
Entity Insert: Uses the statement class to build a dynamic SQL query based on primary keys at runtime. This operation inserts a single entity.
-
-
Output Type: The response type for the connector. Options include a report (providing details such as the executed query, status, and affected row count) or the enrichment of the original user input data.
-
Ignore Fields: A comma-separated list of fields to ignore to avoid exceptions caused by missing fields in the database metadata (For Report output type only).
-
Validate on Rows Affected: Specifies the validation the connector should perform on the row count affected after executing a query.
-
Schema Name: An optional string specifying the name of your schema. This overrides the value in the connection (MariaDB does not use schemas)
-
SQL Query: A string that defines the SQL query to be used (Note: For more than one statement separated by a semicolon, you need to append a connection property allowMultiQueries=true to the database URL) (Only available in Standard Insert)
-
Join Transaction?: A boolean that allows the operation to join an existing transaction.
-
Transaction Id: A string defining the ID for the transaction (Only visible if Join Transaction is enabled).
-
Edit Metadata?: A boolean that when enabled allows manual modification of the metadata (When selected the browser will not update).
-
Metadata: A string value containing all information about a table's fields, which is automatically generated by the browse but can also be provided manually.
-
Batch Behavior: A string specifying the way batching should behave if some items within the batch do not match up.
-
Advanced Settings: Enabling this parameter grants access to additional customization options for more specific configurations.
- CSV Delimiter: Specifies the character used to separate fields within a CSV file.
Input Format
{
"column name": "value"
}
Update Operation
| Video Type | Link |
|---|---|
| Setting up standard update operation | https://drive.google.com/file/d/1ji6s2w_L-yF40Tjpp1Nz9LEaRMSTmoAz/preview |
| Setting up dynamic update operation | https://drive.google.com/file/d/1HbbMaiU6LdTP_HAAkkkWbNSixNyk7vWw/preview |
| Setting up entity update operation | https://drive.google.com/file/d/11sn6IoYkJGHG6HgHPSnZ0J3B3vuHuuKx/preview |
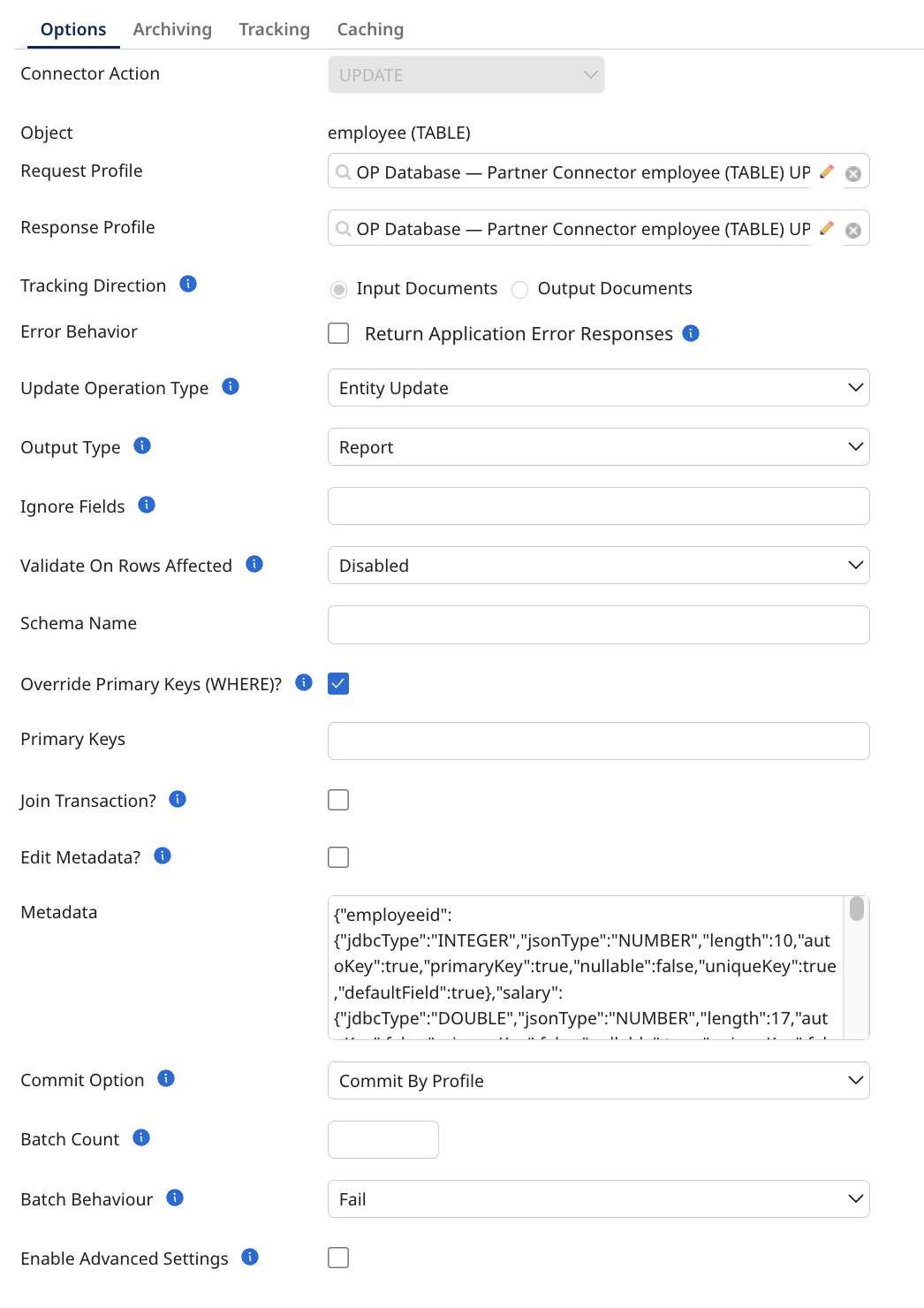
The Update operation is an outbound action used to update records in a database table. The connector operates with single-mode-like behavior. It takes JSON documents as input and provides a JSON response document with the results. You can configure this operation using the following parameters:
-
Update Operation Type: A string specifying the type of update operation to use. The available options are:
-
Dynamic Update: The query is built by the connector at runtime based on user input.
-
Standard Update: The user provides the SQL statement and input parameters, and the connector executes the query based on the input.
-
Entity Update: Uses the statement class to build a dynamic SQL query based on primary keys at runtime. This operation updates a single entity.
-
-
Output Type: The response type for the connector. Options include a report (providing details such as the executed query, status, and affected row count) or the enrichment of the original user input data.
-
Ignore Fields: A comma-separated list of fields to ignore to avoid exceptions caused by missing fields in the database metadata (For Report output type only).
-
Validate on Rows Affected: Specifies the validation the connector should perform on the row count affected after executing a query.
-
Schema Name: An optional string specifying the name of your schema. This overrides the value in the connection (MariaDB does not use schemas).
-
Override Primary Keys (WHERE)?: A boolean that when enabled allows manual modification of the primary keys (Only available in Entity Update).
-
Primary Keys (WHERE): A comma-separated list of all the primary keys that will be used to query the database. (WARNING: If left empty, it will affect all records!) (This will only be used if override primary keys is set to true) (Only available in Entity Update)
-
Sort By Columns: A comma-separated list of all the columns to sort by (This will only be used if override primary keys is set to true) (Only available in Entity Update)
-
Retrieve Columns: A comma-separated list of all the columns to return (This will only be used if override primary keys is set to true) (Only available in Entity Update)
-
SQL Query: A string that defines the SQL query to be used (Note: For more than one statement separated by a semicolon you need to append a connection property
allowMultiQueries=trueto the database URL) (Only available in Standard Update). -
Join Transaction?: A boolean that allows the operation to join an existing transaction.
-
Transaction Id: A string defining the ID for the transaction (Only visible if Join Transaction is enabled).
-
Commit Option: A string that sets the commit behavior when the connector
writes to the database. Options include Commit By Profile (default) or Commit By Number of Rows. (Only visible when Join Transaction isfalse) -
Batch Count: An integer that sets the number of prepared statements to be
batched. (Only visible when Join Transaction isfalse) -
Edit Metadata?: A boolean that when enabled allows manual modification of the metadata (When selected the browser will not update).
-
Metadata: A string value containing all information about a table's fields, which is automatically generated by the browse but can also be provided manually.
-
Batch Behavior: A string specifying the way batching should behave if some
items within the batch do not match up. Options include Fail (default) or Split Batch. (Only visible when Join Transaction isfalse, ignored in Standard Insert) -
Advanced Settings: Enabling this parameter grants access to additional customization options for more specific configurations.
- CSV Delimiter: Specifies the character used to separate fields within a CSV file.
Input Format
Dynamic Update
{
"SET": [
{
"column": "column name",
"value": "value"
}
],
"WHERE": [
{
"column": "column name",
"operatior" "operator symbol (e.g. =)",
"value": "value"
}
]
}
Entity & Standard Update
{
"column name": "value"
}
Stored Procedure Operation
| Video Type | Link |
|---|---|
| Setting up stored procedure operation | https://drive.google.com/file/d/1sAajk9VZKRSDzJURAMIPkipELBk3imOT/preview |
Currently, MariaDB has an issue where a failure in one batch causes all subsequent batches to fail as well.
The Stored Procedure operation executes a procedure in the database. It uses callable statements to call the procedure, and the request/response profiles support input, output, and INOUT parameters of the procedure. If the procedure returns a result set, it is displayed in the response after successful execution. This operation supports JDBC batching if the procedure has only input parameters. You can configure this operation using the following parameters:
-
Output Type: The response type for the connector. Options include a report (providing details such as the executed query, status, and affected row count) or the enrichment of the original user input data.
-
Ignore Fields: A comma-separated list of fields to ignore to avoid exceptions caused by missing fields in the database metadata (For Report output type only).
-
Validate on Rows Affected: Specifies the validation the connector should perform on the row count affected after executing a query.
-
Join Transaction?: A boolean that allows the operation to join an existing transaction
-
Transaction Id: A string defining the ID for the transaction (Only visible if Join Transaction is enabled)
-
Batch Count: An integer specifying the number of records retrieved per output document for document batching
-
Stored Procedure Query Format: A string that specifies if the call statement should be wrapped in curly brackets
-
Edit Metadata?: A boolean that when enabled allows manual modification of the metadata (When selected the browser will not update)
-
Metadata: A string value containing all information about a table's fields, which is automatically generated by the browse but can also be provided manually
-
Max Field Size: An optional integer specifies the limit for the maximum number of bytes that can be returned for character and binary column values in a ResultSetObject produced by this Statement object. If the limit is exceeded, the excess data is silently discarded. Applies only to
-
BINARY
-
VARBINARY
-
LONGVARBINARY
-
CHAR
-
VARCHAR
-
NCHAR
-
NVARCHAR
-
LONGNVARCHAR
-
LONGVARCHAR
-
-
Schema Name: An optional string specifying the name of your schema. This overrides the value in the connection (MariaDB does not use schemas)
-
Fetch Size: An optional integer specifying the number of rows fetched when there is more than one row of result on select statements
-
Advanced Settings: Enabling this parameter grants access to additional customization options for more specific configurations.
- CSV Delimiter: Specifies the character used to separate fields within a CSV file.
Input Format
{
"a": "value"
}
Upsert Operation
| Video Type | Link |
|---|---|
| Setting up upsert operation | https://drive.google.com/file/d/1hCpe4Ej7uh0n6xo3elznEZqJDKHQxKlq/preview |
The Upsert operation allows input to automatically either insert a new row or update an existing row in the database. The operation first determines the conflicting keys, and then automatically inserts or updates the data. When successful, the affected row count is displayed in the response if Commit by Profile is used. In batching, upon successful execution, the batch number and number of records are displayed. The connector supports only dynamic generation of SQL statements based on input parameters. You can configure this operation using the following parameters:
-
Output Type: The response type for the connector. Options include a report (providing details such as the executed query, status, and affected row count) or the enrichment of the original user input data.
-
Ignore Fields: A comma-separated list of fields to ignore to avoid exceptions caused by missing fields in the database metadata (For Report output type only).
-
Validate on Rows Affected: Specifies the validation the connector should perform on the row count affected after executing a query.
-
Schema Name: An optional string specifying the name of your schema. This overrides the value in the connection (MariaDB does not use schemas)
-
Primary Keys: A comma-separated list of all the primary keys that will be used to query the database (WARNING: If left empty, it will affect all records!)
-
Force Casting: A boolean that defines whether the database requires casting for each field on upsert statements
-
Join Transaction?: A boolean that allows the operation to join an existing transaction
-
Transaction Id: A string defining the ID for the transaction (Only visible if Join Transaction is enabled)
-
Commit Option: A string that sets the commit behavior when the connector
writes to the database. Options include Commit By Profile (default) or Commit By Number of Rows. (Only visible when Join Transaction isfalse) -
Batch Count: An integer that sets the number of prepared statements to be
batched. (Only visible when Join Transaction isfalse) -
Edit Metadata?: A boolean that when enabled allows manual modification of the metadata (When selected the browser will not update)
-
Metadata: A string value containing all information about a table's fields, which is automatically generated by the browse but can also be provided manually.
-
Advanced Settings: Enabling this parameter grants access to additional customization options for more specific configurations.
- CSV Delimiter: Specifies the character used to separate fields within a CSV file.
Input Format
{
"column name": "value"
}
Delete Operation
| Video Type | Link |
|---|---|
| Setting up standard delete operation | https://drive.google.com/file/d/1sC6Vyi3L5grYfKJoTLFmc7CQleOkYELh/preview |
| Setting up dynamic delete operation | https://drive.google.com/file/d/1HvX6zvBit0vGUet71Rh9juPYfHZsJY8a/preview |
| Setting up entity delete operation | https://drive.google.com/file/d/1mTDa1QIA8pqFAimPNPQkDghvc6Mspnl9/preview |
The Delete operation is an outbound action used to delete records from the database based on inputs and SQL statements provided by the user. It operates with multi-model-like behaviour. JSON documents are taken as input, and the deleted records appear as a JSON response. You can configure this operation using the following parameters:
-
Delete Operation Type: A string specifying the type of delete operation to use. The available options are:
-
Dynamic Delete: The query is built by the connector at runtime based on user input.
-
Standard Delete: The user provides the SQL statement and input parameters, and the connector executes the query based on the input.
-
Entity Delete: Uses the statement class to build a dynamic SQL query during runtime based on primary keys. This operation deletes a single entity.
-
-
Output Type: The response type for the connector. Options include a report (providing details such as the executed query, status, and affected row count) or the enrichment of the original user input data.
-
Ignore Fields: A comma-separated list of fields to ignore to avoid exceptions caused by missing fields in the database metadata (For Report output type only).
-
Validate on Rows Affected: Specifies the validation the connector should perform on the row count affected after executing a query.
-
Schema Name: An optional string specifying the name of your schema. This overrides the value in the connection (MariaDB does not use schemas)
-
Override Primary Keys (WHERE)?: A boolean that allows manual modification of the primary keys (Only available in Entity Delete)
-
Primary Keys (WHERE): A comma-separated list of all the primary keys that will be used to query the database (WARNING: If left empty, it will affect all records!)
-
SQL Query: A string that defines the SQL query to be used (Note: For more than one statement separated by a semicolon you need to append a connection property allowMultiQueries=true to the database URL) (Only available in Standard Delete)
-
Join Transaction?: A boolean that allows the operation to join an existing transaction.
-
Transaction Id: A string defining the ID for the transaction (Only visible if Join Transaction is enabled)
-
Commit Option: A string that sets the commit behavior when the connector
writes to the database. Options include Commit By Profile (default) or Commit By Number of Rows. (Only visible when Join Transaction isfalse) -
Batch Count: An integer that sets the number of prepared statements to be
batched. (Only visible when Join Transaction isfalse) -
Edit Metadata?: A boolean that when enabled allows manual modification of the metadata (When selected the browser will not update)
-
Metadata: A string value containing all information about a table's fields, which is automatically generated by the browse but can also be provided manually.
-
Batch Behavior: A string specifying the way batching should behave if some
items within the batch do not match up. Options include Fail (default) or Split
Batch. (Only visible when Join Transaction isfalse, ignored in Standard Delete) -
Advanced Settings: Enabling this parameter grants access to additional customization options for more specific configurations.
- CSV Delimiter: Specifies the character used to separate fields within a CSV file.
Dynamic Delete
{
"WHERE": [
{
"column": "column name",
"operatior" "operator symbol (e.g. =)",
"value": "value"
}
]
}
Entity & Standard Delete
{
"column name": "value"
}
Execute Write SQL Query Operation
This operation takes a write SQL query as input, executes it on the database, and handles the response. It is used for modifying data, such as inserting, updating, or deleting records.
Execute Read SQL Query Operation
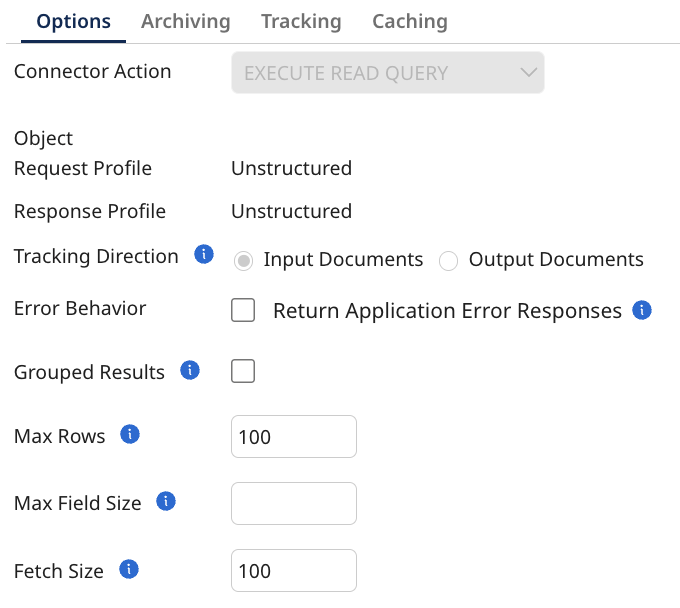
This operation takes a read SQL query as input, executes it on the database, and returns the result. It is used for retrieving data from tables using queries like SELECT.
-
Max Rows: An optional integer that specifies the maximum number of rows to be returned from the database in a single request.
-
Max Field Size: An optional integer specifies the limit for the maximum number of bytes that can be returned for character and binary column values in a ResultSetObject produced by this Statement object. If the limit is exceeded, the excess data is silently discarded. Applies only to
-
BINARY
-
VARBINARY
-
LONGVARBINARY
-
CHAR
-
VARCHAR
-
NCHAR
-
NVARCHAR
-
LONGNVARCHAR
-
LONGVARCHAR
-
-
Fetch Size: An optional integer specifying the number of rows fetched when there is more than one row of results on select statements
Version Operation
Outputs the version of the build to ensure there are no mismatches between what Boomi says is being used and what is being used.
Transaction Start
This creates a new connection dedicated to the transaction and associates it with a unique transaction key. You can either use the default global transaction or provide a custom Transaction ID (required if more than one transaction is open at the same time).
- Transaction Id: The transaction id for the transaction that this operation is a part of. NOTE: This is only applicable if it is part of a transaction, and you do not want to use the global transaction.
Transaction Save Point
This sets a savepoint at the current stage of the transaction. You can either use the default global transaction or provide a Transaction ID. Additionally, you need to provide an ID for the savepoint.
-
Transaction Id: The transaction id for the transaction that this operation is a part of. NOTE: This is only applicable if it is part of a transaction, and you do not want to use the global transaction.
-
Save Point Id: The save point id for the transaction that this operation is a part of.
Transaction Commit
This ends the transaction. You can either use the default global transaction or provide a Transaction ID.
- Transaction Id: The transaction id for the transaction that this operation is a part of. NOTE: This is only applicable if it is part of a transaction, and you do not want to use the global transaction.
Transaction Rollback
This undoes all operations performed after the savepoint was created, returning the transaction to the state it was in at that point.
-
Transaction Id: The transaction id for the transaction that this operation is a part of. NOTE: This is only applicable if it is part of a transaction, and you do not want to use the global transaction.
-
Save Point Id: The save point id for the transaction that this operation is a part of.
