Find Changes step
Use the Find Changes shape to detect how records change between the current process execution and the previously stored state. This shape supports change data capture (CDC) by routing added, updated, and deleted records into separate paths.

The Find Changes step is part of the Advanced Workflow and is available only in the Professional, Professional Plus, Enterprise, and Enterprise Plus Editions of Integration. Contact your Boomi account representative for more information.
Overview
The Find Changes shape compares the current document set to the previously stored data from the last successful run. It identifies records that are new, modified, or missing and routes them to the Add, Update, or Delete paths. After a successful execution, the shape updates the stored state so the next run compares against the most recent data.
On the first execution, when no previous data exists, all records route to the Add path. From the second execution onward, the shape compares records using the configured profile and key fields. Accurate comparisons require consistent profiles and encoding.
The Find Changes shape is most effective when you always retrieve a full dataset from the source system, such as in mainframe extracts or nightly batch files. If your source supports incremental change queries, use those instead for better performance.
If the incoming document set does not contain a complete set of records, the shape treats missing records as deletes and routes them to the Delete path.
If you test the Find Changes step on a local Runtime, reset the stored state before deploying to production. To reset it, delete the process files from the <atom_installation_directory>/work/cdc/<component_ID_of_process> directory.
When to use the Find Changes step
Use the Find Changes step when:
- You receive a full dataset on every run and must detect adds, updates, and deletes.
- The source system cannot provide incremental change queries (for example, no "updated since" filter).
- You need a lightweight change data capture (CDC) solution inside your Boomi process.
- Record structure and keys remain stable across executions.
If the incoming document set is not a complete set of all records, the Find Changes step treats missing records as deletes.
Use this shape only when you always retrieve a full dataset; otherwise, you may generate false deletions.
How the shape works
-
The shape loads the stored data from the last successful run.
-
It receives the current document set from the inbound path.
-
It uses the configured key field(s) to match records between the previous and current sets.
-
It compares each matched record based on the profile structure.
-
It routes the record down the Add, Update, or Delete path.
-
After a successful run, the stored previous data updates to reflect the current state.
If your process encounters an error after the Find Changes shape executes, the stored previous data may not update. This can cause unexpected results in the next execution.
If you use the Find Changes step within a sub process, ensure the configuration does not conflict with other processes. The Runtime stores the state of the Find Changes step in the <atom_installation_directory>/work/cdc directory using a file path based on the Main Process ID and the unique Step Number from the component XML.
If you call the same sub process from different main processes, or if two sub processes share the same internal step number for this shape, the executions will overwrite the same tracking file. To prevent data corruption or inaccurate change detection, use unique Find Changes steps within the same main process or ensure each sub process has a unique identity.
Configuration
Input Streams
You connect two inbound document paths:
-
The first path supplies the previous data.
-
The second path supplies the current data that you want to compare.
The shape treats the first inbound stream as the baseline for comparison.
Key Field Selection
You define a unique key field that identifies each record. This field:
-
Must uniquely identify each record
-
Must appear in both document sets
-
Determines how records match across runs
Profile and Encoding
-
Use the same document profile (Flat File, XML, JSON, JSON Array, etc.) across both inputs.
noteThe Find Changes step supports multi-record flat file profiles when the profile defines a repeating record element. The step evaluates each repeating record using the configured key field.
Profiles that do not include a repeating record structure, or that contain mixed record types without a shared key, are not supported. -
Maintain consistent character encoding across sources and Runtime (for example, UTF-8).
-
Mismatched encoding may cause incorrect Add/Update/Delete results.
Output Paths
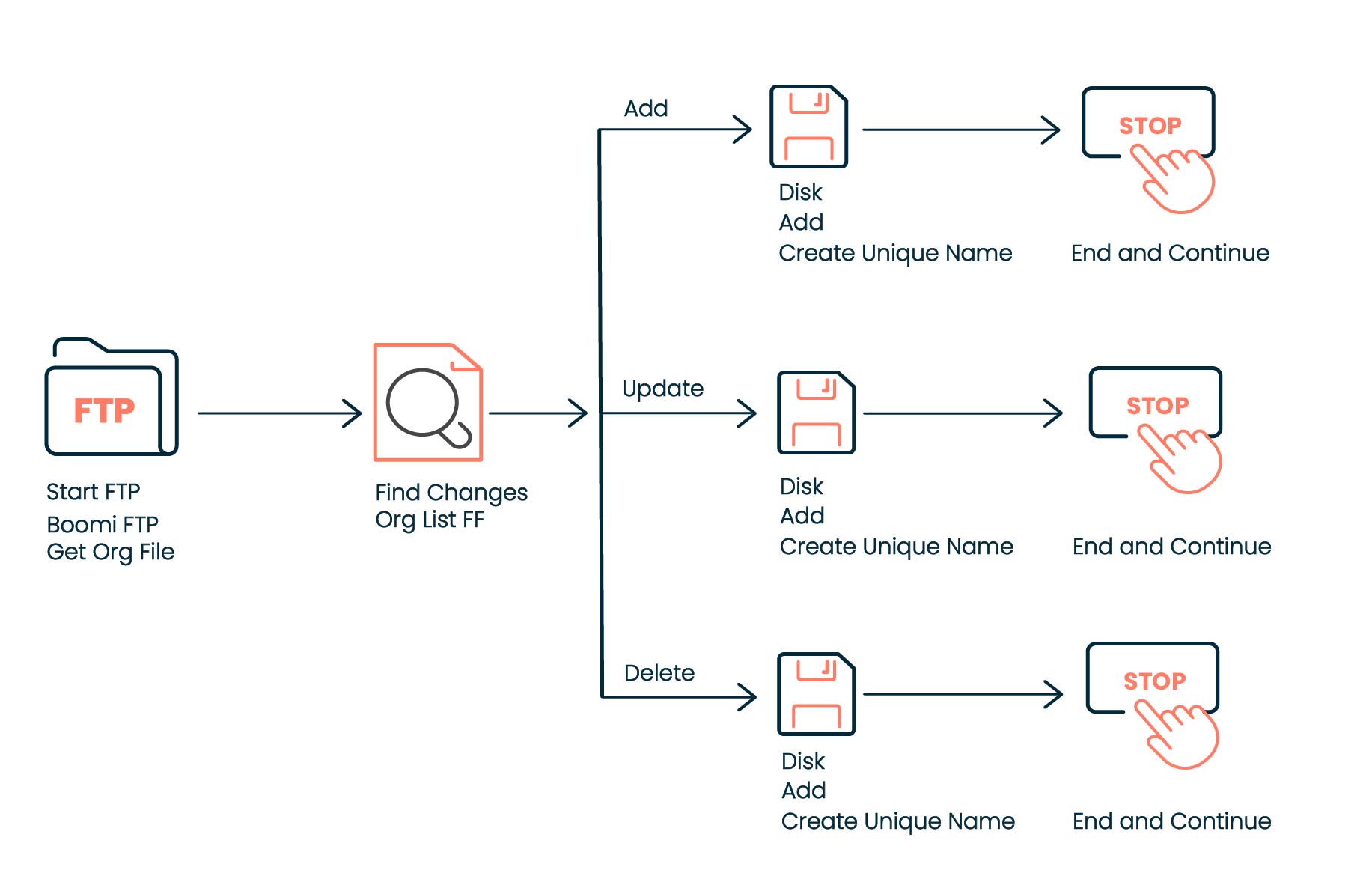
The Find Changes shape provides three output paths:
-
Add — Records that exist in the current data but not in the previous data
-
Update — Records that exist in both sets but whose values changed
-
Delete — Records that exist in the previous data but not in the current data
Route each path to the appropriate processing logic based on your integration requirements.
Configure the Find Changes step
-
Drag the Find Changes step onto the process canvas. The Find Changes dialog opens.
-
Enter a name in the Display Name field. If you leave this field blank, the step displays as Find Changes.
-
Select a document type from the Document Type menu that represents the structure of the data you want to track.
-
Select a profile in the Profile field from the list of available profiles.
-
Add one or more key columns:
-
Click the plus icon in the Key Column section.
-
Select the profile elements that uniquely identify each record.
-
Ensure the selected key columns contain stable, non-changing values so the step can accurately match records across process runs.
The dialog highlights invalid key columns. A key column becomes invalid if the profile changes—for example, if the element is removed or replaced with a new element of the same name but with different internal identifiers. Remove the invalid key column and add the correct one to resolve the issue.
- Click OK to save your configuration and close the dialog.
Maintenance and reset
You may need to reset the stored previous data when:
-
You change the document structure or profile
-
You modify key fields
-
You move or copy the process between environments
-
You want to reprocess all records as new
You can reset by deleting the stored previous data on the Atom or by running the process with an empty incoming set to start fresh.
Known Considerations
-
Behavior may differ slightly between local Runtime and cloud Runtime.
-
If the process fails after the Find Changes shape, the previous data may not update.
-
Consistent profiles and encoding are essential for accurate comparisons.
-
The shape always compares records using the entire profile structure.
Best practices
-
Use a stable, non-changing unique key field.
-
Maintain consistent record structure and encoding.
-
Add logging steps after each output path to verify Add/Update/Delete routing.
-
Wrap this shape and subsequent steps in a Try/Catch sequence to avoid partial updates.
-
Test the configuration with a small dataset before using it with large volumes.
Troubleshooting
-
No Changes Detected: Often caused by misconfigured key fields or profile mismatch.
-
Stale Deletes: “Delete” route never triggered, because the snapshot was never cleared, so old records persist in the tracked state.
-
State File Corruption: In rare cases, the state file may get corrupted (especially in self-hosted Atom). Solution: stop the atom, delete the CDC state file, restart.
-
Unexpected Duplicates: If key is not unique, you might see duplicates in Add or Update path; fix by refining key selection.
For more information, watch the Find Changes Step Overview video.
Example
How Find Changes handles different data formats
The following examples illustrate how the Find Changes step processes Flat File, XML, and JSON data to detect additions, updates, and deletions based on a tracked key field.
Flat File Example
A daily flat file contains a list of client records. The process tracks changes using the AccountID key column. Each day, the file is retrieved from an FTP directory and compared against the previous run. Any changed, new, or missing records are routed to the appropriate path.
-
Execution 1 — Initial Load:
All account records are treated as new and sent down the Add path as individual documents. -
Execution 2 — No Changes:
The daily file has no differences. No documents are routed to any path. -
Execution 3 — Deleted Records:
Three accounts are missing in the latest file. These accounts are routed individually to the Delete path using their previously stored versions.
XML and JSON examples
The Find Changes step behaves the same way for XML and JSON documents.
As long as the profile defines a repeating element (XML) or array of objects (JSON) and a unique key field, the shape detects Add, Update, and Delete events exactly as in the flat file example.
Typical patterns include:
- Initial run: All records route to the Add path.
- Unchanged data: No records route to any path.
- Updated records: Only changed elements route to Update.
- Missing records: Records not present in the latest dataset route to Delete using their previously stored versions.
