Offline flows technical overview
The content on this page is outdated and will not receive updates. For the most up-to-date feature, refer to Setting up and managing flows.
A technical explanation of how offline flows work in comparison to a normal online Flow.
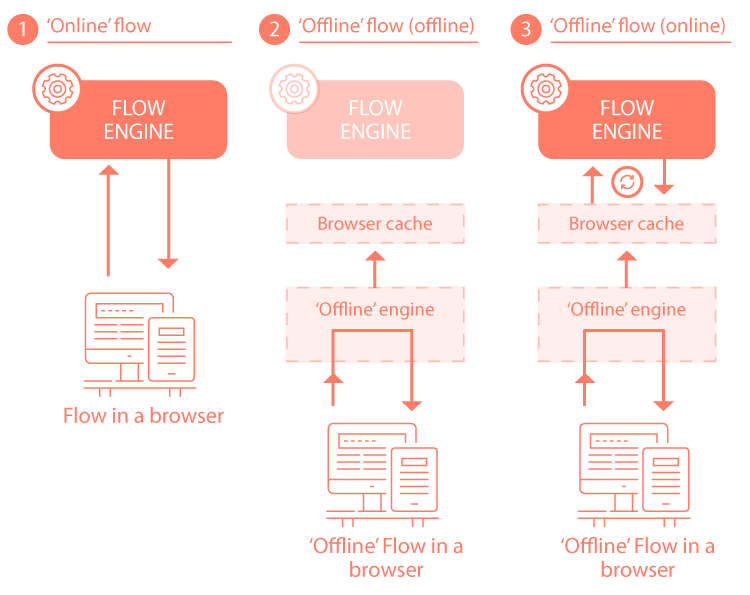
1. 'Online' Flow
In a normal 'online' Flow, the client browser will communicate directly with the online Flow engine.
2. 'Offline' Flow (offline)
-
If a Flow is configured to work 'offline', when it is then accessed in an 'offline' scenario (where there is no internet connectivity), the Flow will no longer communicate with the online Flow engine, but will instead switch to communicating with the offline Flow engine instead.
-
It will do this by using the locally cached Flow metadata in the Flow snapshot to simulate online behaviour, acting as if it were communicating directly with the online Flow engine itself.
-
As a user moves through the Flow, the captured data is saved to a cache in the client browser.
3. 'Offline' Flow (online)
-
Once the user has online connectivity again, they must decide what should happen with the cached data requests, for example whether to replay and apply all the cached requests in sequence, replay requests out of sequence, or delete the requests entirely.
-
Only once the requests have been replayed will the Flow resume normal communication with the online Flow engine. Until these requests have been replayed, the Flow will still operate in 'offline' mode.
If the Flow is protected with authentication and the user's previous session has timed out, the user will be asked to re-authenticate before they can replay and apply the cached requests.`](#).
