Targets overview
The Data Integration Targets include data warehouses and data storage. Configure targets based on requirements.
Supported targets
Refer to the sections below for instructions on connecting to each target type:
Flows and key concepts when loading into DWH targets
Key concepts
ELT
Data Integration loading and transformation methods use the ELT (Extract, Load, Transform) approach. This process minimizes transformation bottlenecks during loading and ensures the high performance of the target databases by performing transformations directly within them.
Managing data and metadata
To ensure the data represents the accurate and complete truth, Data Integration loads and transforms the data over the pipeline with the Target tables. The platform does not drop, change, alter, or update the Target table or its data in case of failures.
Data Integration platform ensures that the data in the table, and the metadata of the table, remain complete as defined in the Data Flow. This guarantees no data loss, incomplete data, or changes in the table structure, even if the Data Flow fails to complete its run.
Configuring file zone
To prevent data loss and reduce dependency on the source when loading data into the target, Data Integration stores the data in a cloud storage service—such as AWS S3, Google Cloud Storage, or Azure Blob Storage—referred to as the File Zone.
Data Integration preserves data even during load failures. Any failure during the loading step does not result in data loss. The platform maintains the extracted data to prevent redundant source requests.
Data warehouse (DWH) Data Flow types
Source to Target Flows
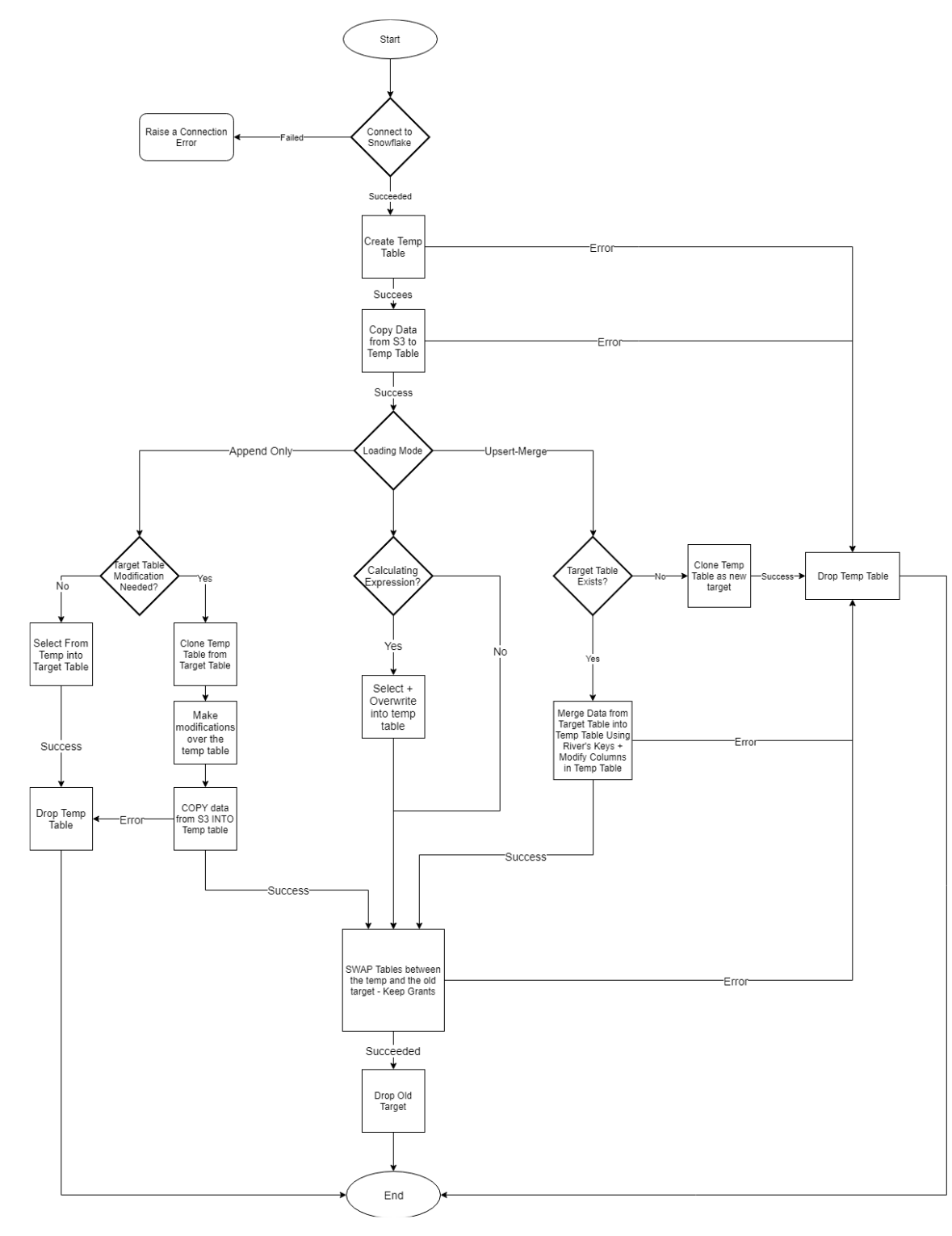
Source to Target Flows pull data from sources and load it into the target databases via the File Zone. The Source to Target Flow handles the Extract and Load phases of the ELT process. Each pipeline configuration can load the data using Overwrite, Append Only, or Upsert Merge modes.
Logic Flow
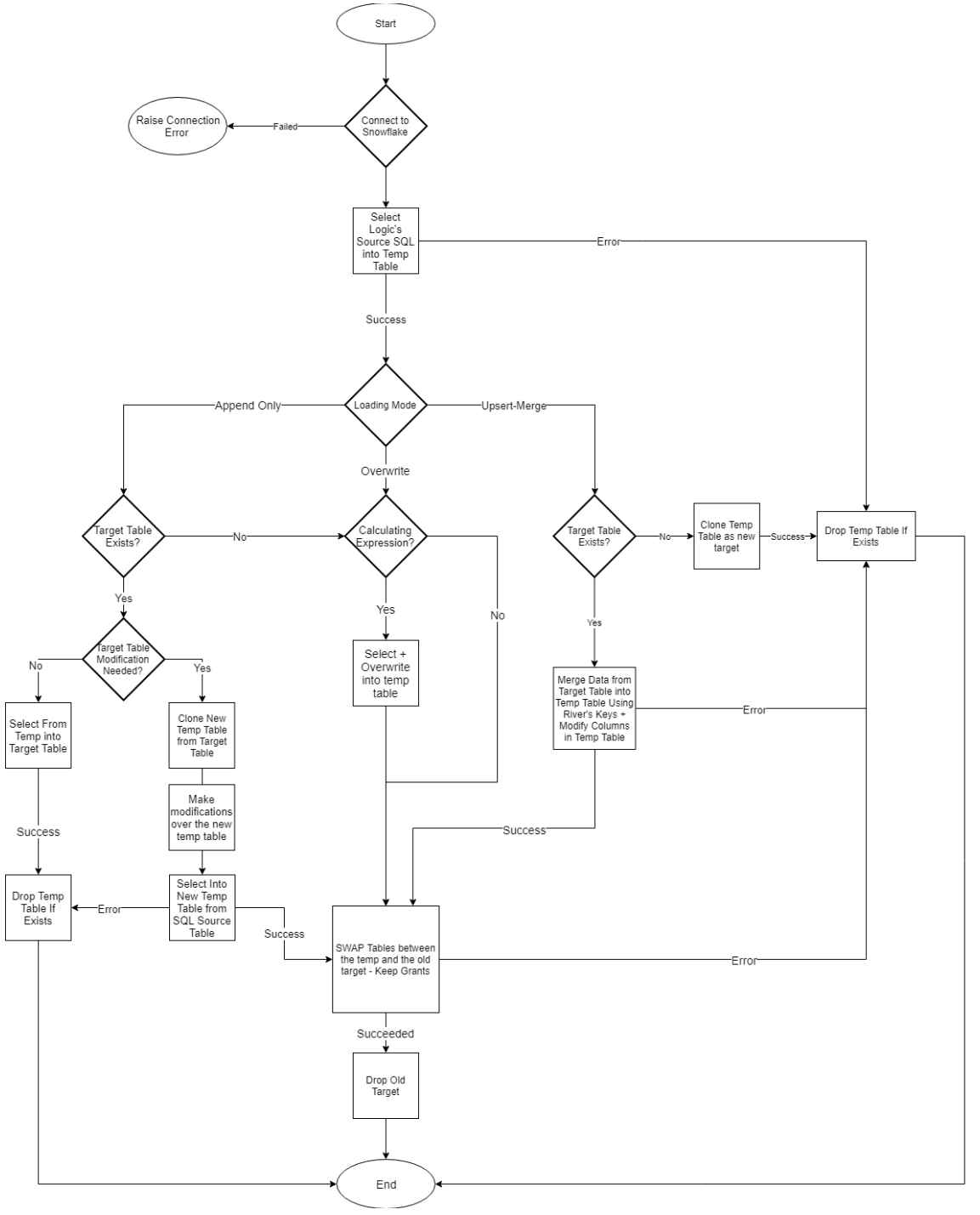
An innovative engine handles the Transform phase in the ELT process. This Data Flow type runs SQL queries steps over the Database, manages and selects query results into tables in the DWH or into file(s) in the File Zone.
The Logic Flow steps can run in parallel, via a loop over a list, by condition, or step by step, and can also use smart variables.
Loading flowcharts
Source to Target Flow: loading data into the target table flowchart
Logic Flow
Logic Flow: selecting into the target table flowchart