MySQL CDC overview
CDC extraction
Data Integration Log-Based extraction mode provides a real-time stream of any changes made to the databases and tables configured, eliminating the need to implement and maintain incremental fields or retrieve data via select queries. It also enables you to retrieve deleted rows and schema changes from the database.
CDC extraction configured in MySQL
The MySQL CDC mechanism relies on its binary log (binlog). Like all databases, you must explicitly enable logging for MySQL to ensure that Change Data Capture is taking place. MySQL Server includes this feature pre-built. Enabling this log is a straightforward operation in MySQL — you must set up the three parameters correctly in your MySQL database server:
-
binlog_format -
binlog_row_image -
expire_logs_days
Configuring the expire_logs_days parameter to an appropriate value is essential to ensure bringing data from the log constantly. The key trade-off is between storage usage and the ability to keep enough log history to recover from failures. Setting expire_logs_days too high can consume excessive storage on the MySQL server or cluster, while setting it too low risks purging logs before Data Integration can retrieve them if the connector encounters an issue.
For Data Integration, the recommended value for expire_logs_days is 7 days. This strikes a practical balance between _binlog_ storage requirements and the retention needed to support reliable recovery in the event of failure fetching the log.
CDC Point in Time position feature
The CDC Point in Time position feature lets you gain deeper insights into the operational details of a Data Flow's streaming process. This feature is essential for data recovery and synchronization, enabling you to locate and retrieve data from a specific point in history using the exact information stored in the CDC log position. For more information, refer to our CDC Point in Time position.
CDC extraction work in Data Integration
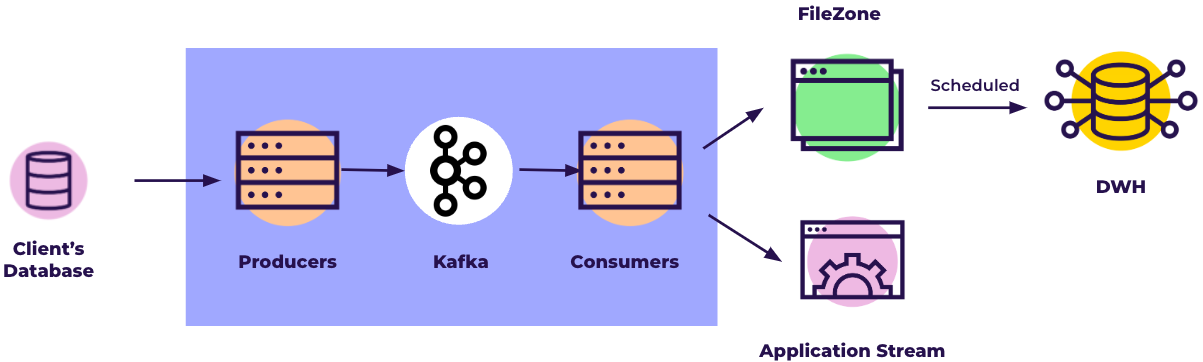
To pull data using the Change Data Capture architecture, Data Integration continuously pulls new rows written in the binlog. Data Integration cannot rely on the entire log history existing before setting up a Data Flow to get the historical data from the database. MySQL maintains and purges the binlog after some period of time (defined using the expire_logs_days parameter).
To align the data and the metadata in the first run, Data Integration makes a complete snapshot (or migration ) of the chosen table(s) using the Overwrite loading mode. After the migration ends successfully, Data Integration takes the existing binlog records and makes an Upsert-merge __ to the target table(s), continuing to fetch new records from the log as MySQL creates them.
The MySQL connector in Data Integration reads the binlog records and produces change events for row-level INSERT , UPDATE, and DELETE commands into the FileZonefiles. Each file represents a group of operations made in the database in a specific time frame. Data Integration streams the data from the log constantly (in time frames of up to 15 minutes) into the FileZone path specified in the Data Flow and pushes it into the target according to the Data Flow's scheduled frequency. Data Integration saves the data first in the FileZone and can then push it into the target DWH at any time.
For more information about the FileZone configuration in Data Integration, refer to the target configuration.
A Sequence CDC deployment
Discrepancies in transaction records can occur when two users simultaneously execute identical transactions, resulting in conflicts in the timestamp field. Recognizing this challenge, Data Integration implemented a Sequence Change Data Capture (CDC) mechanism.
Data Integration has enhanced each emitted record from the database by incorporating two extra metadata fields: __transaction_id and __transaction_order.
-
The _
_transaction_idfield serves as a unique identifier for each transaction, ensuring that no two transactions share the same identifier. This uniqueness enables precise identification and differentiation between transactions, mitigating conflicts arising from identical timestamps. -
The
__transaction_orderfield denotes the order in which the database emitted the transactions. By incorporating this field, Data Integration accurately maintains the sequencing of transactions, enabling downstream systems such as Apache Kafka or AWS Kinesis to process and order transactions correctly.
The inclusion of these metadata fields guarantees that Data Integration preserves the ordering of transactions throughout the Data Flow. As a result, Data Integration achieves smooth and accurate transaction flows, resolving the discrepancies that arose from transactions with identical timestamps.
For further details about Change Data Capture (CDC) Metadata Fields, refer to our Database Overview document.
Architecture diagram
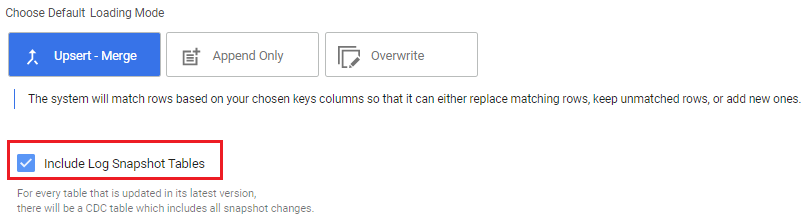
Load tables with log-snapshot tables
Loading your data from a database to a target using CDC has an additional capability of pulling the log snapshot table.
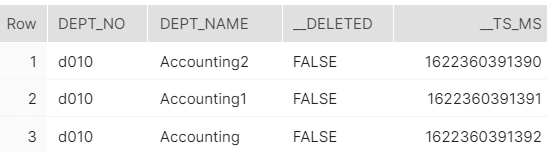
Using the following use case table:
](../../../../../Images/image-1622372498020.png)
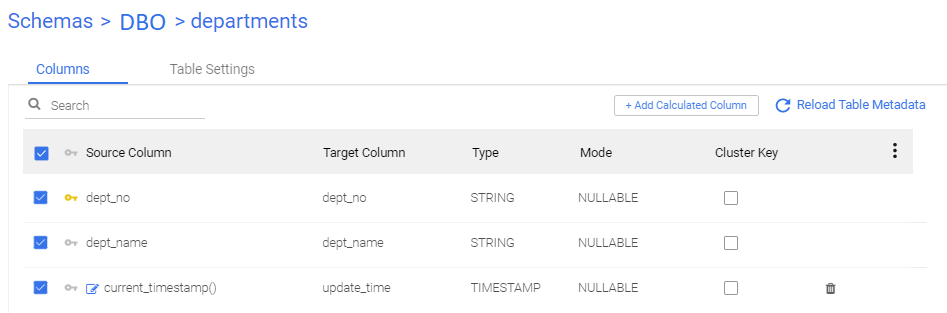
To attach each log snapshot table to its respective table, use the same naming convention with the suffix _log. For example, if you pass DEPARTMENTS to the target using CDC, then DEPARTMENTS_LOG is its respective log snapshot.
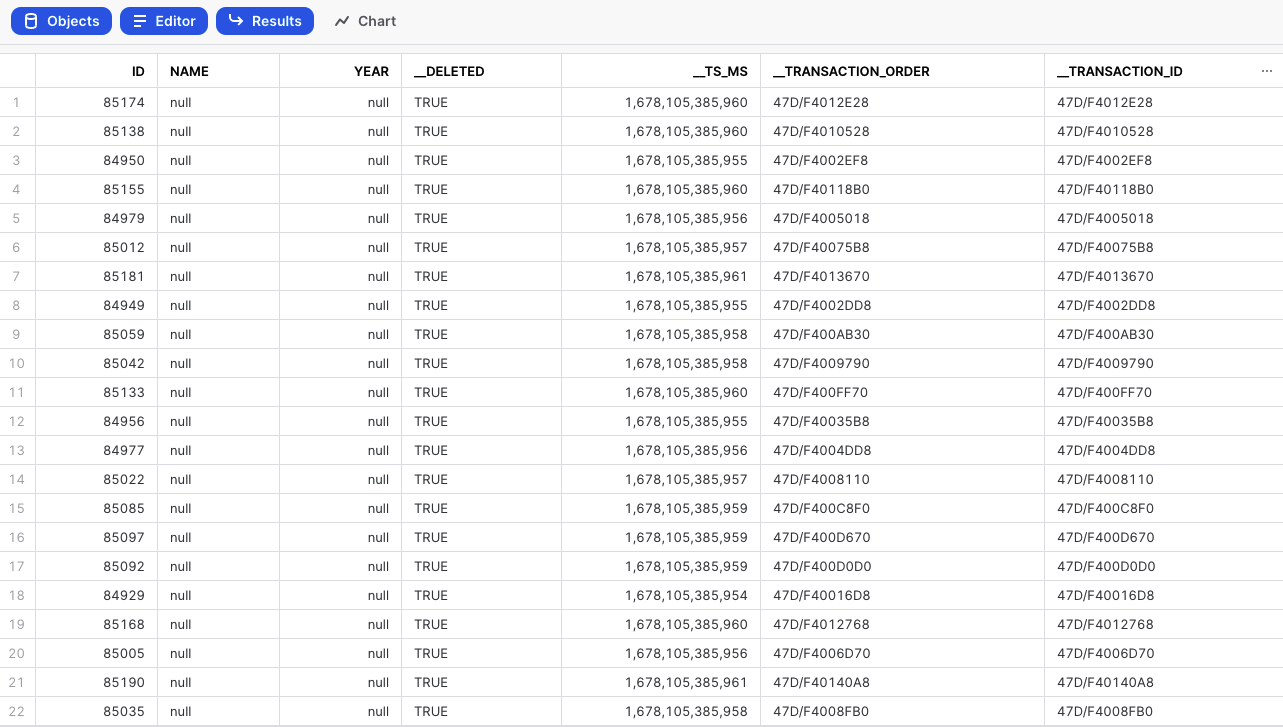
The platform records each action performed on the log snapshot table as a new entry, along with when the change occurred (in the __ts_ms column) and whether the platform deleted the record (in the __deleted column).
The __DELETED column is available only when a delete action occurs.
The platform treats _log tables as append-only, and in the event of a connection issue, the platform pulls data from the last successful pull to prevent any data loss. As a result, _log tables may contain duplicate records.
The original table:

In the DBO.DEPARTMENTS table, there are two columns: DEPT_NO and DEPT_NAME. Additionally, there is a calculated expression in the target's mapping which uses current_timestamp().
Before enabling CDC (Change Data Capture) and migrating the Data Flows, the automatically included fields __deleted and __ts_ms have null values for all records.
Data Integration loads the log snapshot table only when you set the Status to Streaming:
These are the possible configurations when using CDC:
Each Data Flow starts with the status Waiting For Migration, and takes everything currently present in the table.

Scheduling
After the first run, Data Integration changes the status to Streaming and loads the log snapshot tables. The scheduling of the Data Flows provides details about the frequency of writing logs to the file zone; you can change this option later in the Data Flow's Settings and Schedule.
