SQL server CDC walkthrough
Change data capture extraction
SQL Server Change Data Capture (CDC) simplifies the extract, transform, and load processes. It also records data changes such as inserts, deletes, and updates, but it provides more details than SQL Server Change Tracking. The capture mechanism and the information it captures differ.
Change Data Capture retrieves information by querying the online transaction log on a regular basis. The procedure is asynchronous. This approach does not affect database performance, and it adds less overhead than other solutions (for example, using triggers).
SQL Server CDC requires no schema changes to existing tables, adds no timestamp columns to the tracked (source) tables, and creates no triggers. SQL Server collects data and stores it in change tables.
When you apply CDC to a table, SQL Server automatically creates a second table to track all DML (inserts, updates, and deletes) to the table. SQL Server internally tracks all DML to the base table by reading committed transactions from the transaction log, like how SQL Server implements replication. SQL Server reads this log in the background, adding no additional work to the originating transaction.
- SQL Server requires a CDC table to have a Primary Key for the CDC mechanism to track it.
- Data Integration does not support the
@index_nameoption.
CDC point in time position feature
The CDC Point in Time position feature lets you gain deeper insights into the operational details of a Data Flow's streaming process. This feature is essential for data recovery and synchronization, enabling you to locate and retrieve data from a specific point in history using the exact information stored in the CDC log position. For more information, refer to our CDC Point in Time position topic.
A Sequence CDC deployment
Discrepancies in transaction records can arise when two users simultaneously execute identical transactions, causing conflicts in the timestamp field. Data Integration implemented a sequence Change Data Capture (CDC) mechanism to tackle this issue.
Data Integration enhances each emitted record from the database by incorporating two extra metadata fields: __transaction_id and __transaction_order.
-
The
__transaction_idfield serves as a unique identifier for each transaction, ensuring that no two transactions share the same identifier. This uniqueness provides precise identification and differentiation between transactions, mitigating conflicts arising from identical timestamps. -
The
__transaction_orderfield denotes the order in which the database emitted the transactions. By incorporating this field, you can accurately maintain the sequencing of transactions, enabling downstream systems such as Apache Kafka or AWS Kinesis to process and order transactions correctly.
The inclusion of these metadata fields guarantees that Data Flow preserves the ordering of transactions throughout the Flow. As a result, Data Integration achieves smooth and accurate transaction flows, resolving the discrepancies that arose from transactions with identical timestamps.
This table shows the additional fields:
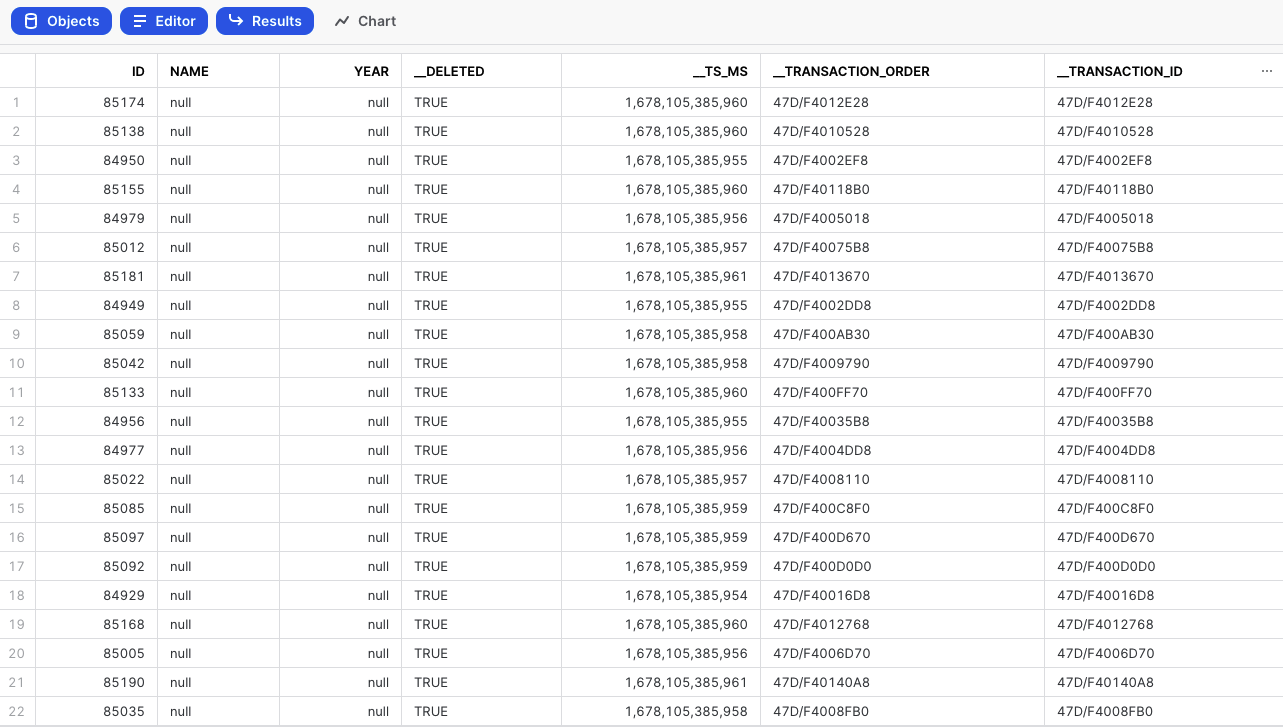
For further details about Change Data Capture (CDC) Metadata Fields, refer to Database Overview document.
Architecture diagram
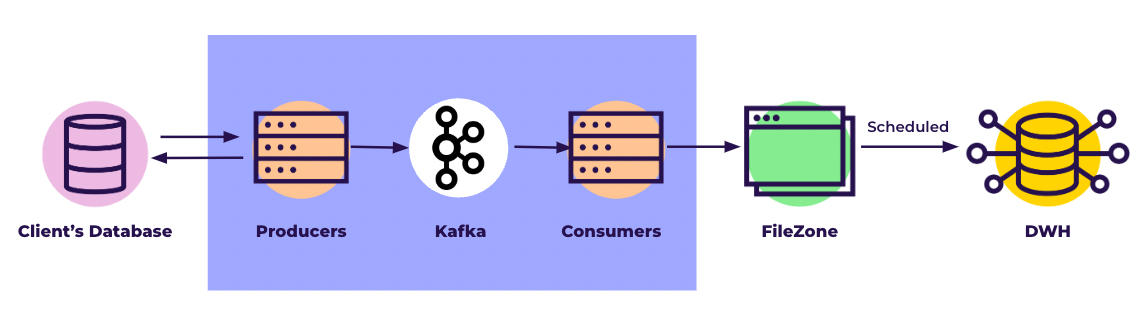
- Producers - The process that reads the changes made to the source database.
- Kafka - Streaming service to ensure that Kafka delivers changes securely and reliably.
- Consumers - The process that reads the Kafka Stream and saves the changes as files.
- FileZone - The storage that holds the files Data Integration loads into the target data store.
- DWH - The target Data Warehouse into which Data Integration loads the changes.
