Cluster Topologies
This page illustrates the architecture for setting up single-zone and multi-zone clusters.
Single Zone
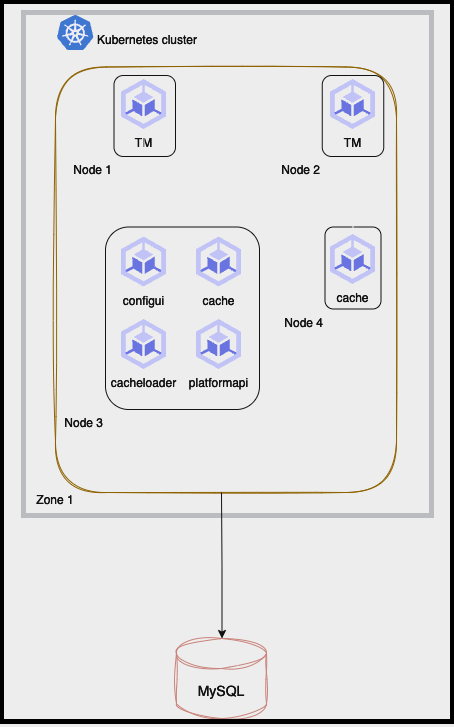
This diagram shows the components and communication flow within a single-zone cluster.
Architecture diagram: single-zone cluster
Multi Zone
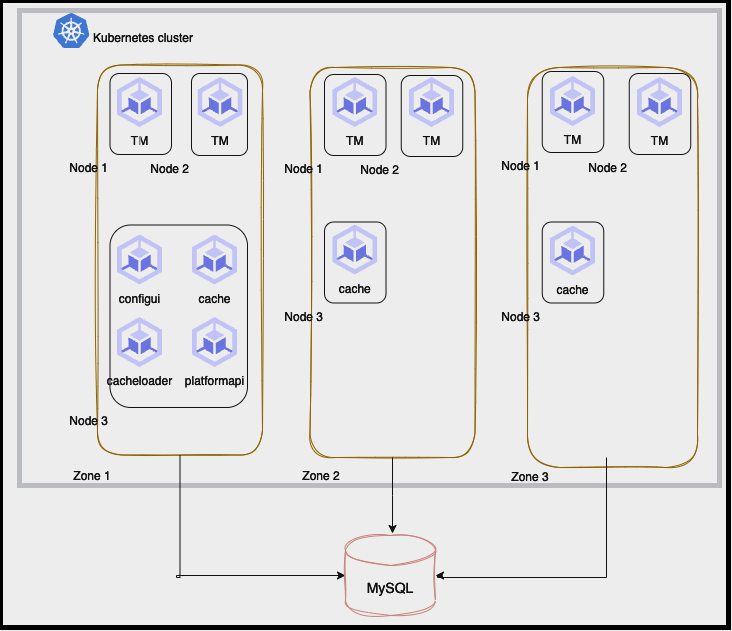
This diagram shows the components and communication flow within a multi-zone cluster.
Architecture diagram: multi-zone cluster
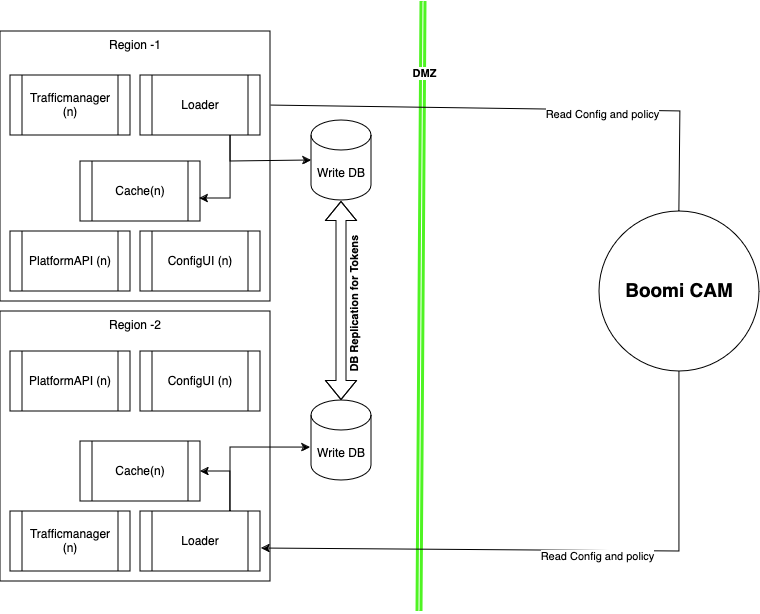
Active-Active Setup in Tethered Mode (introduced in v6.1.0)
Active-Active Setup in Tethered mode for Boomi Cloud API Management – Local Edition (LE) was introduced in v6.1.0 and is not supported in earlier versions.
Each region has its own writable database with replication configured to share tokens. Alternatively, to enable HA within each region, you can use a single database with multiple read replicas.
Boomi Cloud API Management has updated configurations and policies, so you do not have to enable replication for them.
Loader Scheduling Guidelines for Shared Database Clusters
When multiple Cloud API Management – Local Edition clusters share the same database, it is important to prevent concurrent loader operations that may block database writes.
Use the following guidelines to configure safe and efficient cron schedules:
-
Start clusters one at a time
Start and wait for each Cloud API Management - Local Edition cluster one at a time to be ready, to ensure that multiple loaders do not attempt to write to the database simultaneously. -
Stagger loader cron schedules
Adjust the Kubernetes cron schedules forloadercronchart in each installation (refer to the 6.2.0 Values.yaml in the Installation Guide) so that clusters do not run loader jobs simultaneously.Example schedule across three clusters
The table below shows a sample loader job schedule for three clusters sharing the same database:
Job Cluster 1 Cluster 2 Cluster 3 Interval loader-job-onprem00:00 00:05 00:10 15 min loader-job-full00:00 01:00 02:00 24 hrs loader-job-delta00:00 00:05 00:10 15 min -
Each cluster runs the same job at different times to avoid simultaneous database writes.
-
The Interval column indicates how often each job repeats per cluster:
loader-job-full→ every 24 hoursloader-job-onpremandloader-job-delta→ every 15 minutes
importantStaggering loader jobs across clusters ensures that multiple clusters do not write to the shared database simultaneously, preventing conflicts and maintaining data consistency.
-
Small Topology
-
Number of nodes:
-
Minimum: 2
-
Recommended: 4
-
-
Zones: Single us-east4-a
-
ConfigUI: 1
-
PlatformAPI: 1
-
Cache:
-
Minimum: 2
-
Recommended: 3
-
-
TrafficManager:
-
Minimum: 2
-
Recommended: 3
-
-
Loader (CacheLoader in v6.0.0; Loader from v6.1.0+): 1
-
Target QPS: 500
Medium Topology
-
Number of nodes:
-
Minimum: 3
-
Recommended: 9
-
-
Zones: Multizone
-
us-east4-a
-
us-east4-b
-
us-east4-c
-
-
ConfigUI: 1
-
PlatformAPI: 1
-
Cache: 3
-
TrafficManager:
-
Minimum: 3
-
Recommended: 6
-
-
Loader(CacheLoader in v6.0.0; Loader from v6.1.0+): 1
-
Target QPS: 500, 1500, and 3000.
Java Virtual Machine sizing
-
TM JVM starting (-Xms) /maximum (-Xmx) heap size parameters were set to 4GB.
-
cache, cache starting/maximum heap size were set to 1GB.
-
PlatformAPI maximum heap size was set to 2GB
Small Cluster
-
2 cache and 2 Traffic Manager pods are sharing nodes located in the same zone. Each node runs one Traffic Manager pod and one cache pod.
-
PlatformAPI, Config-UI, and Loader (CacheLoader in v6.0.0; Loader from v6.1.0+) pods are also on the same nodes as they have no direct role during Traffic calls.
-
Traffic volume: 500 QPS.
-
Application logs and access logs of all pods are forwarded to a dedicated OpenSearch cluster.
- No resource limits are added against any pod
Medium Cluster
-
3-node cluster, one node per zone.
-
3 cache and 3 traffic manager pods. Each node (and therefore zone) hosts one cache and one TM pod.
-
PlatformAPI, ConfigUI and Loader (CacheLoader in v6.0.0; Loader from v6.1.0+) pods run the same nodes as they have no direct role during traffic calls and use few resources.
-
Traffic volume: 500/1500/3000 QPS.
-
Application logs and access logs of all pods are forwarded to a dedicated OpenSearch cluster.
-
No resource limits are set for any pod.
-
TM JVM starting/maximum heap size - 4GB
Generated traffic model
-
25% protected and 75% unprotected traffic
-
Request Size is constant: 2kb
-
Response size distribution of traffic:
72% traffic → Size 0-4kb (Random distribution of response sizes → 2b,1kb, 2kb, 4kb)
28% traffic → Size 4kb -16kb (Random distribution of response sizes → 4kb, 8kb, 16kb)
-
Minimum response time from Latency Injectors are configured to be 1 millisecond.
-
No Token generation calls are included.
-
20 Endpoints with quota set at unlimited (i.e. no counters) used for unprotected traffic and 20 endpoints used for protected traffic with high (50,000,000) daily quota and throttle (20,000,000) values.
